Modelli linguistici e agenti AI: le nuove frontiere per imprese e ricerca
I modelli transformer continuano a crescere nelle dimensioni e nelle performance. Stanno trovando anche nuove e più vaste applicazioni, con impatti sempre più rilevanti sui sistemi produttivi, sulle imprese, sulla società e la vita delle persone.
Mentre le imprese e le pubbliche amministrazioni sperimentano l’introduzione di nuove soluzioni AI all’interno dei propri processi e dell’organizzazione, big tech, startup e centri di ricerca si sfidano per realizzare i modelli fondazionali più potenti e applicazioni più efficaci.
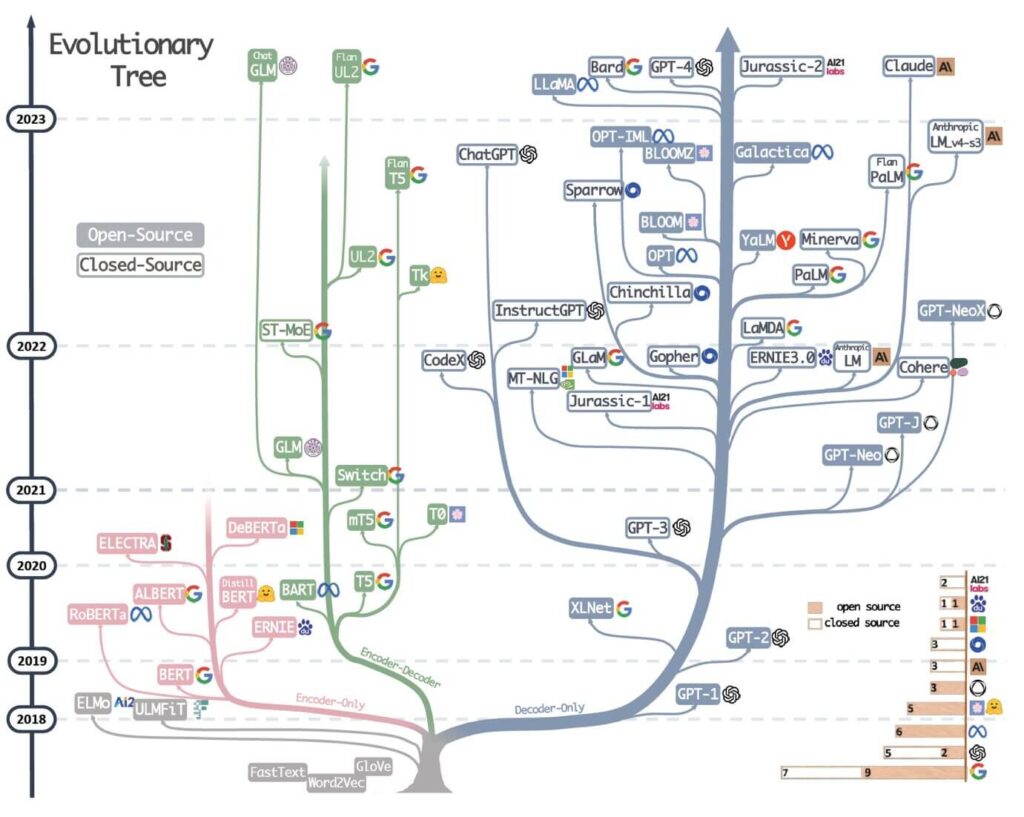
Figura 1: l’evolutionary tree dei moderni large language model mostra la radice comune e la vivacità della “competizione” tra i diversi modelli disponibili, sia open-source e proprietari; mostra anche il ruolo centrale giocato da un pugno di imprese, le poche big tech e startup con capacità finanziaria e tecnologica per addestrare modelli di grandi dimensioni. Immagine tratta da: Jingfeng Yang et al, Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond, 2023
Proprio l’utilizzo dei modelli fondazionali per la creazione di applicazioni enterprise è l’oggetto di questo articolo, in cui proveremo a tracciare un quadro delle direzioni in cui si stanno muovendo le imprese e la ricerca. Per farlo, affronteremo questi temi:
- LLM: limiti, possibilità e performance di frontiera
- Specializzazione dei modelli attraverso Retrival Augmented Generation (RAG)
- Modelli per la generazione di dati sintetici
- Modelli multimodali
- Agenti generativi e chain of thoughts: dal contenuto all’azione
- Robot e intelligenza fisica
Lo faremo, mostrando alcune applicazioni sviluppate dalle imprese, tra cui alcune soluzioni realizzate dal team Data & Artificial Intelligence di P4I e una selezione di pubblicazioni scientifiche recenti.
LLM: possibilità e limiti delle performance attuali
Il primo tema è quello delle performance: fino a dove arrivano oggi gli llm e quali performance possono garantire?
I modelli linguistici di grandi dimensioni (LLM) hanno dimostrato prestazioni eccezionali in una vasta gamma di compiti e applicazioni: in questa prima parte degli anni 20, i progressi ne migliorano in maniera continuativa le capacità, grazie alla crescita delle dimensioni dei modelli (con un effetto scaling per certi versi imprevisto perfino dai ricercatori) e migliorandone / specializzandone le prestazione attraverso il fine-tuning. La sfida è rendere i modelli più affidabili, integrati ad applicazioni di uso comune, estendendone l’uso a compiti complessi. Rispetto alla comprensione del linguaggio naturale e all’elaborazione multimodale sono stati fatti passi avanti notevoli, anche solo negli ultimi mesi.
Nonostante ciò, rimane vero che i modelli generalisti non sono in grado di risolvere nemmeno il 2% dei problemi matematici presenti in FrontierMath, un benchmark di problemi matematici recentemente sviluppato da un gruppo di scienziati per misurare le capacità di ragionamento logico matematico degli LLM. (https://arxiv.org/abs/2411.04872)
Figura 2: Percentuale di problemi matematici compresi all’interno del benchmark FrontierMath risolti dai principali modelli linguistici di grandi dimensioni. Come si vede, siamo ancora lontani da una supposta super-intelligenza. Per approfondimenti
Come si diceva, i modelli linguistici di grandi dimensioni mostrano performance eccezionali, per certi versi impreviste e sorprendenti anche per i ricercatori che li hanno studiati e sviluppati tutta la vita. Si parla infatti di capacità emergenti, che non sono presenti nei modelli di “piccole” dimensioni, ma che compaiono, a un certo punto, al raggiungimento di una certa scala.
Figura 3: Alcuni esempi di capacità emergenti in diversi modelli. Come si vede, al crescere della dimensione del modello (scale) si osserva una discontinuità importante nel livello di accuratezza dello stesso. Per approfondimenti
La svolta nella costruzione di modelli così potenti è stata resa possibile grazie alla crescita delle capacità computazionali e di storage e alla quantità di dati disponibili e processabili. Secondo il Prof. Giuseppe Attardi dell’Università di Pisa (in questa lezione pubblicamente disponibile una panoramica sintetica e molto efficace di cosa sono gli llm e come sono fatti) ci sono state però tre grandi innovazioni negli algoritmi che hanno reso possibile il salto di qualità di questi ultimi anni nelle performance, ovvero:
- Word Embedding
- Modelli transformer e meccanismo dell’attenzione
- Prompt
Figura 4: embeddings e rappresentazione nello spazio multidimensionale delle parole e comprensione del significato. Per approfondimenti e per testare lo spazio semantico delle parole, si veda: https://projector.tensorflow.org/
Grazie al meccanismo di word embedding è possibile rappresentare le parole come vettori dello spazio multidimensionale, in cui posizione relativa dei diversi termini ne restituisce la distanza semantica. Attraverso l’embedding projector sviluppato con Tensorflow, è possibile visualizzare la posizione relativa delle parole e il formarsi di aree semanticamente vicine.
Tramite il meccanismo dell’attenzione e i modelli transformer, introdotti da un paper pubblicato da 8 ricercatori di Google nel 2017, e che si può definire a buon diretto seminale anche per il celeberrimo titolo “Attention is all you need”, si sono realizzati modelli capaci di completare le frasi, selezionando la parola con la probabilità più alta secondo il contesto, considerato proprio grazie al meccanismo dell’attenzione, che riescono a mantenere su un grande numero di parole.
Figura 5: Architettura dei modelli transformer, alla base dei modelli linguistici di grandi dimensioni; fonte
Infine, la terza grande innovazione, ovvero il prompt, la possibilità di interagire con i modelli non attraverso il coding, ma usando semplicemente il linguaggio naturale.
I modelli fondazionali sono dunque dei sistemi in grado “semplicemente” di prevedere la probabilità di occorrenza della parola che completa una frase. Applicazioni specifiche, come ChatGPT, necessitano di ulteriori fasi di fine-tuning, ovvero di specializzazione del modello attraverso istruzioni fornite tramite prompt specifici e un retraining dei parametri del modello con dataset molto specifici e di alta qualità, un aspetto che rende non solo la creazione dei modelli fondazionali, ma anche lo stesso fine-tuning per certi versi complesso e delicato.
Dal lancio di ChatGPT 3.5 da parte di Open AI, il 30 novembre 2022, si è avviata una nuova fase, con il discorso pubblico sull’innovazione (e non solo) focalizzato sull’intelligenza artificiale e con le inevitabili polarizzazioni che un tema così complesso inevitabilmente si porta dietro. Come detto, a guidare l’evoluzione sono le solite note big tech (Microsoft, Google, Meta, Amazon, …) e un pugno di startup dalle immense risorse tecnologiche, finanziarie e cognitive (Open AI, Anthropic, HuggingFace, …), che si confrontano e competono per lo sviluppo di modelli e applicazioni sempre più performanti.
Un momento di grande effervescenza, in le imprese si stanno muovendo, con tempi e risorse diverse per acquisire competenze, tecnologie, startup, sviluppando spesso Proof of Concept e portando anche alcuni applicativi in produzione.
Occorre ricordare, che la storia dell’intelligenza artificiale, in particolare nella declinazione del machine learning, non è certo nata nel novembre 2022, né con gli llm. Sono migliaia le applicazioni pratiche e concrete dell’intelligenza artificiale con cui conviviamo da molti anni: i sistemi anti-frode delle carte di credito, i sistemi di rating per la concessione del credito bancario, i motori di raccomandazione che ci suggeriscono i prodotti sugli eCommerce e i contenuti sulle piattaforme di streaming, i sistemi di visione artificiale nei sistemi di sicurezza, la manutenzione predittiva degli impianti e delle infrastrutture, la previsione della domanda di risorse per l’ottimizzazione delle scorte, ecc.
Per distinguere le applicazioni che conosciamo da tempo dalla novità introdotta dai modelli transformer, si distingue frequentemente tra intelligenza artificiale tradizionale o predittiva e intelligenza artificiale generativa, un termine che comprende meglio la diversa natura, intrinsecamente multimodale dei modelli che non sono solo linguistici.
Per concludere, le applicazioni sono enormi e la ricerca ha dimostrato (anche con la scoperta delle capacità emergenti dei modelli di larghe dimensioni) che gli LLM non sono gli stupidi “pappagalli stocastici”, come li definì alcuni anni fa un gruppo di ricerca multidisciplinare; come visto non siamo neppure arrivati alla singolarità o alla super-intelligenza o all’intelligenza artificiale generale di cui parlano da tempo vari futurologi, tra cui il più famoso resta Ray Kurzweil, che la profetizzata già negli anni zero di questo secolo.
Nel seguito si passeranno in rassegna alcune linee di sviluppo nella ricerca e nell’industria. Vedremo infatti:
- Alcuni esempi di RAG utilizzati per specializzare e rendere sicure le applicazioni custom, che sfruttano motori llm.
- Modelli per la creazione di dati sintetici.
- Modelli multi-modali.
- Agenti generativi autonomi.
RAG e fine-tuning per la specializzazione degli LLM: casi concreti
Come detto, un modello fondazionale non è in sé utilizzabile se non è specializzato e poi inserito in un’applicazione. ChatGPT o Claude Sonnet non sono dei semplici language model, sono delle applicazioni, nella fattispecie dei chatbot: alla base hanno degli llm, che sono però stati inseriti all’interno di applicazioni capaci di fare.
Un primo approccio per specializzare i modelli utilizzare il fine-tuning che ha il vantaggio di specializzare il modello agendo direttamente sui parametri, modificandoli, ma lo svantaggio di richiedere una notevole capacità computazionale e dataset di grandi qualità per il retraining dei parametri.
Per circoscrivere gli output possibili, ridurre i rischi di allucinazioni, bias, comportamenti inattesi, un approccio molto diffuso che ne migliora drasticamente le performance in un ambito specifico di applicazione è costituito dai RAG (Retrieval Augmented Generation), in cui il modello generale, creato dalle grandi imprese tech come Google, Meta, Microsoft, e da startup iperfinanziate come Open AI o Anthropic, su un corpus molto ampio di dati (perlopiù provenienti dal web) è integrato attraverso documentazione specifica a cui il modello deve accedere per reperire le informazioni con cui elaborare le risposte e i contenuti da creare.
Un approccio adatto ad ambiti in cui il corpus di conoscenza è circoscrivibile e descrivibile da una documentazione specialistica, a cui il modello si deve riferire per decodificare il senso, accedere alle informazioni ed elaborare i contenuti richiesti. Insieme a prompt, guardrails e filtri, i RAG rappresentano la principale architettura adottata non solo per specializzare sul contesto specifico il modello, ma anche per limitare i rischi di allucinazioni e comportamenti inappropriati.
Nel seguito, si mostrano 3 esempi di applicazioni basate su RAG realizzate dal team Data & Artificial Intelligence di P4I per applicare dei modelli esistenti in contesti specifici.
Applicazione 1: assistente legale autonomo
Figura 6: l’interfaccia dell’assistente legale sviluppato dal team Data & AI di P4I.
L’applicazione realizzata, basata su GPT4 attraverso un’API, è un chatbot che funge da assistente per avvocati ed esperti legali che hanno la necessità di raccogliere rapidamente da un corpus giuridico ben definito informazioni specifiche; l’applicativo permette all’operatore di ricevere riposte precise e di estrarre singole citazioni dalle fonti identificate, producendo diverse tipologie di output.
Applicazione 2: RAG per il risk management
Figura 7: l’interfaccia del RAG per l’assessment del rischio sviluppato dal team Data & AI di P4I.
In questo caso, il RAG sviluppato è uno strumento a supporto delle funzioni Risk Management, attraverso cui gli analisti possono individuare le diverse tipologie e il grado di rischio e intraprendere azioni per mitigarlo. In questo caso, si è optato per una soluzione sviluppata in ambiente Azure (Azure AI Studio), per garantire una configurazione semplice e sicura, utilizzando servizi già ingegnerizzati.
Applicazione 3: Anonymyzer
Figura 8: architettura dell’anonyzer sviluppato dal team Data & AI di P4I.
In questo caso, si è sviluppata un’applicazione che utilizza un modello BERT fine-tuned, ottimizzato per riconoscere informazioni sensibili (entità) presenti in un testo. App di questo tipo sono fondamentali nel caso in cui si vogliano utilizzare servizi di terze parti come GPT o Claude Sonnet 3.5, mantenendo un’alta protezione di tutti i dati sensibili, che non sono così forniti al modello per il suo retraining, minimizzando i riski di data leak.
Modelli per la generazione di dati sintetici
Il tema dei dati di input, con cui fare il traninig dei modelli, rappresenta una delle aree più delicate nello sviluppo e nell’evoluzione delle applicazioni di IA generativa. Il fine-tuning, come abbiamo visto, richiede dati di grande qualità e molto specifici. Nello stesso tempo, l’utilizzo di dati realizzati da terze parti nel training di un modello apre scenari complessi nella gestione del diritto d’autore. Inoltre, i dati personali in particolare, sono particolarmente delicati e il rischio di data leak o attacchi hacker possono pregiudicare la sicurezza e minacciare la privacy, ovvero causare la diffusione di dati sensibili di diverso tipo. Inoltre, raccogliere dati reali e di qualità sul campo resta un’attività costosa.
Per queste ragioni, si sta sviluppando un mercato di produzione e commercializzazione di dati sintetici; un mercato con grandi aspettative di crescita, fino a raggiungere i 21 miliardi di dollari nel 2028.
Nvidia, uno degli attori principali grazie alla potenza di calcolo delle proprie GPU, con Nemotron ha realizzato un modello specializzato nella creazione di dati sintetici.
Figura 9: Nemotron, il modello di Nvidia per la creazione di dati sintetici. Fonte
Modelli multimodali per un’interazione sempre più naturale con le macchine
L’intelligenza artificiale multimodale utilizza testi, immagini, audio e altri formati di dati per creare una visione più realistica del mondo, vicina al modo in cui il cervello umano lo percepisce.
L’intelligenza artificiale multimodale affronta sfide simili a quelle delle prime forme di intelligenza artificiale generativa, ma all’interno di questioni più complesse e di un accresciuto rischio di non conformità tecnologica e legale.
I Ray-Ban Meta Wayfarer, nati dalla collaborazione tra Essilor-Luxottica e Meta, sono un esempio di applicazione multimodale, in cui immagini fisse, video, audio sono trattati in maniera “naturale” da un oggetto che, per altro, mantiene la propria natura di accessorio di moda. La sfida è enorme, combinando computer vision, audio analysis, text detection e ingegnerizzazione in un prodotto di moda.
Figura 11: Ray-Ban Meta Wayfarer
La frontiera degli agenti generativi autonomi
La direzione su cui la ricerca sta investendo maggiormente è quella degli agenti autonomi, ovvero creazione di cosiddette chain-of-thoughts e worflow (sequenze) di compiti in cui diversi modelli specializzati in un compito diventano input uno dell’altro, permettendo la realizzazione di un compito complesso, come sarebbe svolto da un umano. La differenza tra l’intelligenza umana e quella artificiale è che la seconda è ancora ristretta (narrow), ovvero iper-specializzata e super performante (in molti ambiti anche più di quella umana), ma in un set limitato di contesti e variazioni, con forti limitazioni in ambiti poco codificati e ambienti complessi che includono, ad esempio, lo spazio. Il limite al raggiungimento della cosiddetta AGI (Artificial General Intelligence) è proprio questo. Le architetture con cui si stanno realizzando gli agenti generativi stanno però rendendo sempre meno utopistico il raggiungimento di intelligenze così versatili da essere ancora più vicine a quella delle persone.
Aldilà delle speculazioni filosofiche, gli agenti generativi permettono di risolvere un grande numero di problemi, sempre più complessi e sofisticati. Nel seguito, vediamo come.
Agenti autonomi che interagiscono in un ambiente simulato
Figura 12: Smallville, dove gli agenti generativi hanno iniziato a interagire autonomamente tra di loro. Fonte
Partiamo da un esperimento sviluppato dai ricercatori di Stanford, in cui 25 agenti generativi sono stati inseriti in un ambiente urbano simulato (simile a Sim City). Ciascun agente era dotato di proprie basi cognitive e caratteristiche uniche. Gli agenti, dotati di questa “personalità”, ovvero di istruzioni iniziali, sono stati lasciati interagire tra di loro per due giorni, all’interno di questo ambiente cittadino simulato chiamato Smallville. Dopo questo periodo di interazione, i ricercatori hanno interrogato gli agenti che hanno mostrato capacità di ricordare eventi occorsi in questo periodo non supervisionato, di riflettere su sè stessi e di fare piani coerenti per il futuro. Ma, soprattutto, hanno mostrato un’evoluzione: si sono influenzati a vicenda e si sono trasformati, assorbendo esperienze da un ambiente complesso e dall’interazione con altre entità artificiali.
Agenti autonomi che realizzano pezzi di progetto
Figura 13. Un possibile esempio di modello di funzionamento di un agente autonomo
Alle imprese, interessa che gli agenti generativi possono gestire catene di attività complesse, che richiedono workflow specifici. Se con gli agenti si può interagire usando il linguaggio naturale e questi possono eseguire compiti di una certa complessità, allora significa che possono diventare “colleghi” con cui avremo a che fare in tutti i luoghi di lavoro. Possono per esempio grado di connettersi e attivare software e piattaforme esistenti e interagire con questi. Questa è forse oggi la direttrice di innovazione che promette di avere impatti importanti in tempi relativamente brevi.
In questo video, qualche esempio già attuale di agenti, all’interno dell’ecosistema Microsoft, in grado di svolgere compiti complessi.
AI Reasoning: la simulazione del ragionamento umano e il futuro del lavoro
Figura 14. La realizzazione di un compito complesso tramite Chain-of-Thoughts e workflow codificati e automatizzati. Fonte: Chengxing Xie, Difan Zou, A Human-Like Reasoning Framework for Multi-Phases Planning Task with Large Language Models, 2024
In questo esempio, è stato dimostrato come un compito complesso come la progettazione e prenotazione di una vacanza possa essere svolta da una catena di agenti, interagenti tra di loro, ciascuno specializzato in un compito specifico. Il reasoning, ovvero un ragionamento complesso che tenga in considerazione un grande numero di variabili e della conoscenza tacita, rappresenta un limite per un singolo LLM. Questo studio dimostra che, una soluzione è realizzabile tramite una catena di LLM molto specializzati e inseriti in un processo strutturato (workflow) che divide il ragionamento e il comportamento che le persone tendono a fare in maniera naturale e intuitiva, in fasi bene codificate. Dividendo il compito complessivo, che richiede una pianificazione approfondita fuori dalla partata di un singolo LLM, i ricercatori hanno simulato il ragionamento umano. Nel modello sono infatti definite 3 fasi distinte (outline generation, information collection, plan making) in cui hanno usato diversi modelli, concatenati tra di loro, per realizzare la desiderata pianificazione complessa.
È chiaro che se pensiamo ad un gran numero di attività cognitive, e in particolare diverse attività intellettive non banali – la creazione di un sito web, la scrittura di un piano di business, l’organizzazione di un evento – che oggi richiedono diverse persone, con competenze specifiche, intravediamo un futuro in cui il ruolo degli agenti autonomi sarà tutt’altro che trascurabile.
Robot e intelligenza fisica: gli LLM oltre la manipolazione del linguaggio
Se è vero che la prima industrializzazione, combattuta non a caso dai luddisti, ha trasformato soprattutto il lavoro manuale in contesti di produzione industriale, abbiamo già visto come i computer prima e il machine learning poi hanno sostituito e resi obsoleti molti colletti bianchi. In particolare, prima dell’avvento degli agenti autonomi e dell’IA generativa, addetti a compiti ripetitivi e facilmente automatizzabili.
Una frontiera rimasta esclusivamente umana era quella del lavoro creativo, “minacciato” però oggi dalle capacità dell’IA generativa appunto.
Un’altra frontiera era quella dei compiti intellettuali più complessi e sofisticati, dove il reasoning è particolarmente complesso. Come visto nella sezione precedente, gli agenti generativi e i cosiddetti chain of thoughts promettono di minare anche questa rassicurante convinzione. Neanche le professioni al alto tasso cognitivo sono al riparo.
A fare da baluardo alle attività umane era rimasti alcuni compiti, magari non particolarmente complessi dal punto di vista cognitivo, per quanto riguarda l’elaborazione di informazioni, compito in cui l’intelligenza artificiale eccelle, ma con tanti e complessi elementi di tipo percettivo.
In accordo con il paradosso di Moravec, è più semplice per un robot effettuare ragionamenti complessi che svolgere attività considerate semplici ma che prevedono interazioni non molto codificate con lo spazio fisico. Per questo, Luciano Floridi nel suo Etica dell’intelligenza artificiale parla di un mondo “avvolto” intorno ai robot per rendere possibile lo svolgimento di questi compiti. L’esempio che, molto efficace, è quello della lavastoviglie, in cui non abbiamo costruito un robot umanoide che lava i piatti “a mano”, ma uno strumento che ottiene lo stesso risultato ma con una tecnologia e una modalità di interazione completamente diverse e perfettamente adatta a una macchina, ovvero la lavastoviglie.
In realtà, la ricerca recente, sta dimostrando la possibilità di realizzare robot umanoidi in grado di interagire con lo spazio circostante, di fare ragionamenti complessi e di svolgere compiti poco codificati, come stirare o caricare una lavatrice e stendere, nel modo in cui lo farebbero gli umani.
Figura 15: Physical Intelligence, π0, il robot che svuota la lavatrice, stende, stira i panni, come lo farebbero gli umani. Per approfondire: https://www.xn--1xa.com/blog/pi0
Physical Intelligence ha lanciato π0, un robot general-purpose, basato su un vision-language model che sfrutta l’architettura alla base dei modelli linguistici, utilizzandola in modo da gestire sequenze complesse di azioni nel mondo fisico, dimostrando dunque una grande flessibilità.
Figura 16: Architettura del modello linguistico alla base di π0, il robot realizzato da Physical Intelligence
Il vision-language-action model sviluppato da Pyshical Intelligence e addestrato su dataset open-source per la manipolazione robotica, che includono compiti di destrezza svolti da 8 robot distinti, permette a π0 di eseguire una vasta gamma di compiti, sia tramite prompting zero-shot che fine-tuning, rappresentando una frontiera interessante nello sviluppo dei modelli alla base dell’intelligenza artificiale generativa.
In conclusione, anche per attività che includono competenze percettive e conoscenza dello spazio come quelle tipiche di lavori di costruzione, pulizia, cura delle persone, manutenzione di impianti, ecc., possiamo intravedere un futuro in cui gli agenti autonomi e i robot multi-purpose svolgeranno questi compiti accanto a noi. E questo futuro non è così lontano.
Bibliografia
Chengxing Xie, Difan Zou, A Human-Like Reasoning Framework for Multi-Phases Planning Task with Large Language Models, 2024
Jingfeng Yang et al, Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond, 2023, https://arxiv.org/abs/2304.13712
Elliot Glazer1 et al.,FrontierMath: a benchmark for evaluating advanced mathematical reasoning in AI, novembre 2014: https://arxiv.org/abs/2411.04872
Jason Wei et al., Emergent Abilities of Large Language Models, 2022: https://arxiv.org/abs/2206.07682
Linzhuang Sun et al., BEATS: Optimizing LLM Mathematical Capabilities with BackVerify and Adaptive Disambiguate based Efficient Tree Search, settembre 2024: https://arxiv.org/html/2409.17972v1
ChatGPT, Wikipedia: https://en.wikipedia.org/wiki/ChatGPT
Giuseppe Attardi, Artificially informed, conferenza Fondazione Feltrinelli, aprile 2024: https://www.youtube.com/watch?v=hPFz8QD33T0
Vasani et al., Attention is all you need, 2017: https://arxiv.org/abs/1706.03762
Bender, Gebru, et. al, On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?, 2021: https://dl.acm.org/doi/10.1145/3442188.3445922
Nemotron-4 340B Technical Report, https://research.nvidia.com/publication/2024-06_nemotron-4-340b
AI’s new frontier, MIT Technology Review, https://www.technologyreview.com/2024/05/08/1092009/multimodal-ais-new-frontier/
Computational Agents Exhibit Believable Humanlike Behavior, https://hai.stanford.edu/news/computational-agents-exhibit-believable-humanlike-behavior
Autore del post: Federico Della Bella Fonte: https://www.agendadigitale.eu/feed/ Continua la lettura su: https://www.agendadigitale.eu/industry-4-0/modelli-linguistici-e-agenti-ai-le-nuove-frontiere-per-imprese-e-ricerca/ <span data-mce-type="bookmark" style="display: inline-block; width: 0px; overflow: hidden; line-height: 0;" class="mce_SELRES_start"></span><span data-mce-type="bookmark" style="display: inline-block; width: 0px; overflow: hidden; line-height: 0;" class="mce_SELRES_start"><span data-mce-type="bookmark" style="display: inline-block; width: 0px; overflow: hidden; line-height: 0;" class="mce_SELRES_start"></span></span><span data-mce-type="bookmark" style="display: inline-block; width: 0px; overflow: hidden; line-height: 0;" class="mce_SELRES_start"></span>
Il Ministero delle Pari Opportunità finanzia il tuo corso digitale
📷
Chiedi tutte le informazioni a [email protected]
📷

